Local-first AI CLI usage analytics
TokenTrace
TokenTrace scans local AI CLI artifacts, normalizes token usage, estimates missing counts when necessary, and shows cost, model, project, session, parser, and repair evidence in a local dashboard. No cloud account, no telemetry, no proxying.
npx tokentrace
Runs without installing. Or install globally with npm install -g tokentrace and run tokentrace.
What it does
One local database, every total auditable
Nine surfaces over one local SQLite database, from evidence-first analytics to a first-class MCP entry point. Each tile is the short version. Tap into Features for the full breakdown.
MCP entry point
tokentrace mcp starts a local stdio MCP server. Agents call get_agent_guide first, then pick from a read-only tool surface. run_scan needs explicit human confirmation.
tokentrace mcp Evidence-first overview
Usage Pulse, token accounting, Model Rates, and Trend charts. Every total points back to the records that produced it.
Local Sources & Trust
Reads JSON, JSONL, SQLite, and Cursor exports the AI CLIs already write on disk. Every record carries a Data Confidence score.
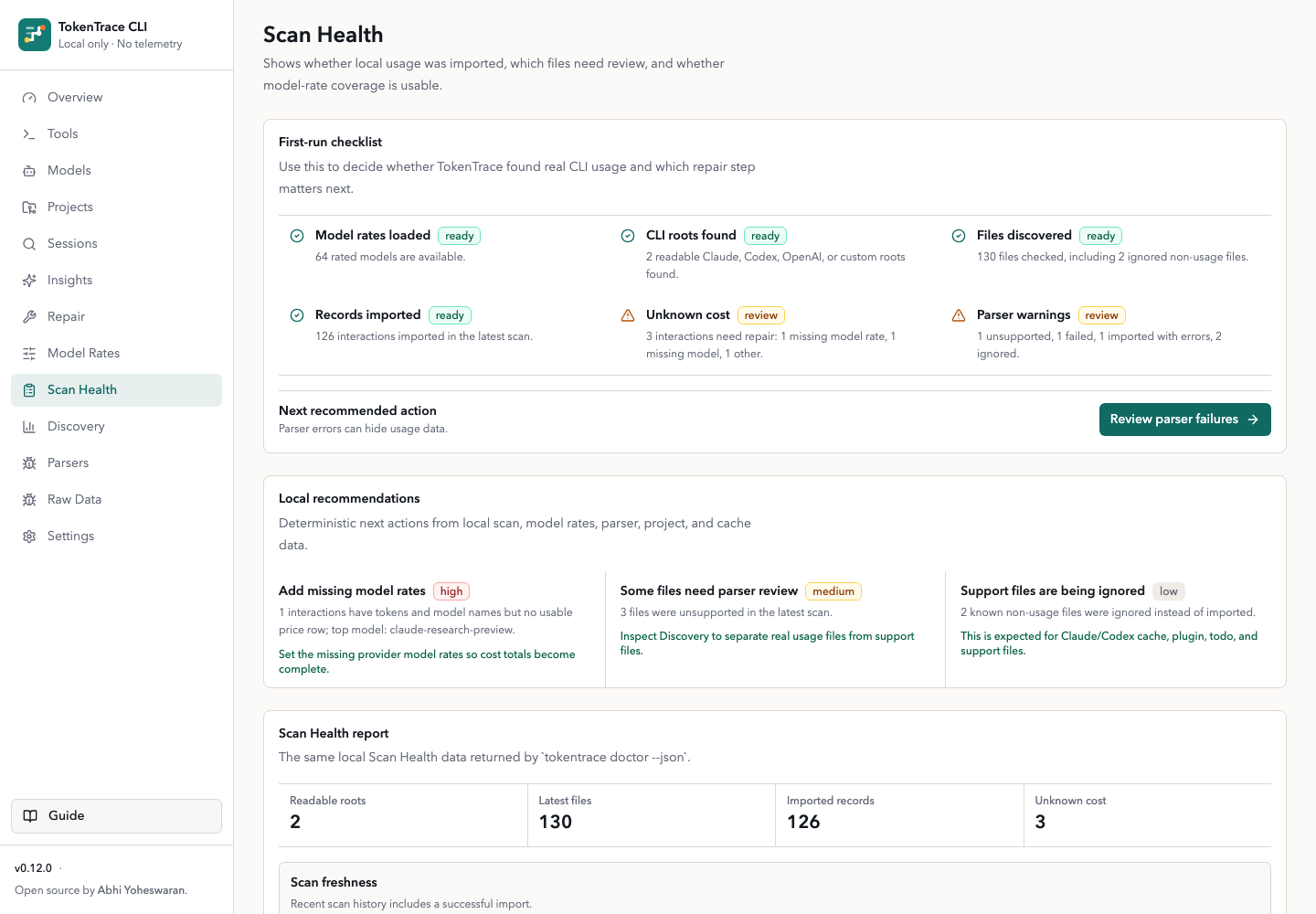
Scan Health
Files checked, Parser warnings, ignored support files, cost coverage, scan scheduling, and supply-chain IOC checks, all in one view.
Repair workflow
Unknown-cost rows grouped by cause, with the next best repair next to the evidence. A before/after delta runs before you commit.
Evidence Packs
Export the trail behind any total as JSON or Markdown. No raw prompts by default, so usage evidence is safe to share.
Agent-ready entry points
A read-only discovery manifest over CLI and HTTP, plus agent-adoption docs and an llms.txt index, so any agent can find the surface.
Performance & mobile
Trend aggregation, first-screen data, lazy Settings, plus mobile card layouts for Repair and Model Rates so the dashboard reads one-handed.
Privacy
No telemetry, no proxy, no cloud account. Local files never leave the machine. The only network call refreshes public Model Rates.
Live status
A live status line for Claude Code
Claude Code renders a custom status line at the bottom of its terminal. TokenTrace plugs into that contract. The line separates live context (what Claude is carrying now) from cumulative processed and cache usage, so you stop misreading "tokens used this session" as "tokens in context now."

Wire it up
tokentrace statusline setup claude # add the printed statusLine block to ~/.claude/settings.json
Codex CLI status-line integration is deferred until its hook contract stabilizes. tokentrace watch --session shows the same status in a terminal split as a fallback.
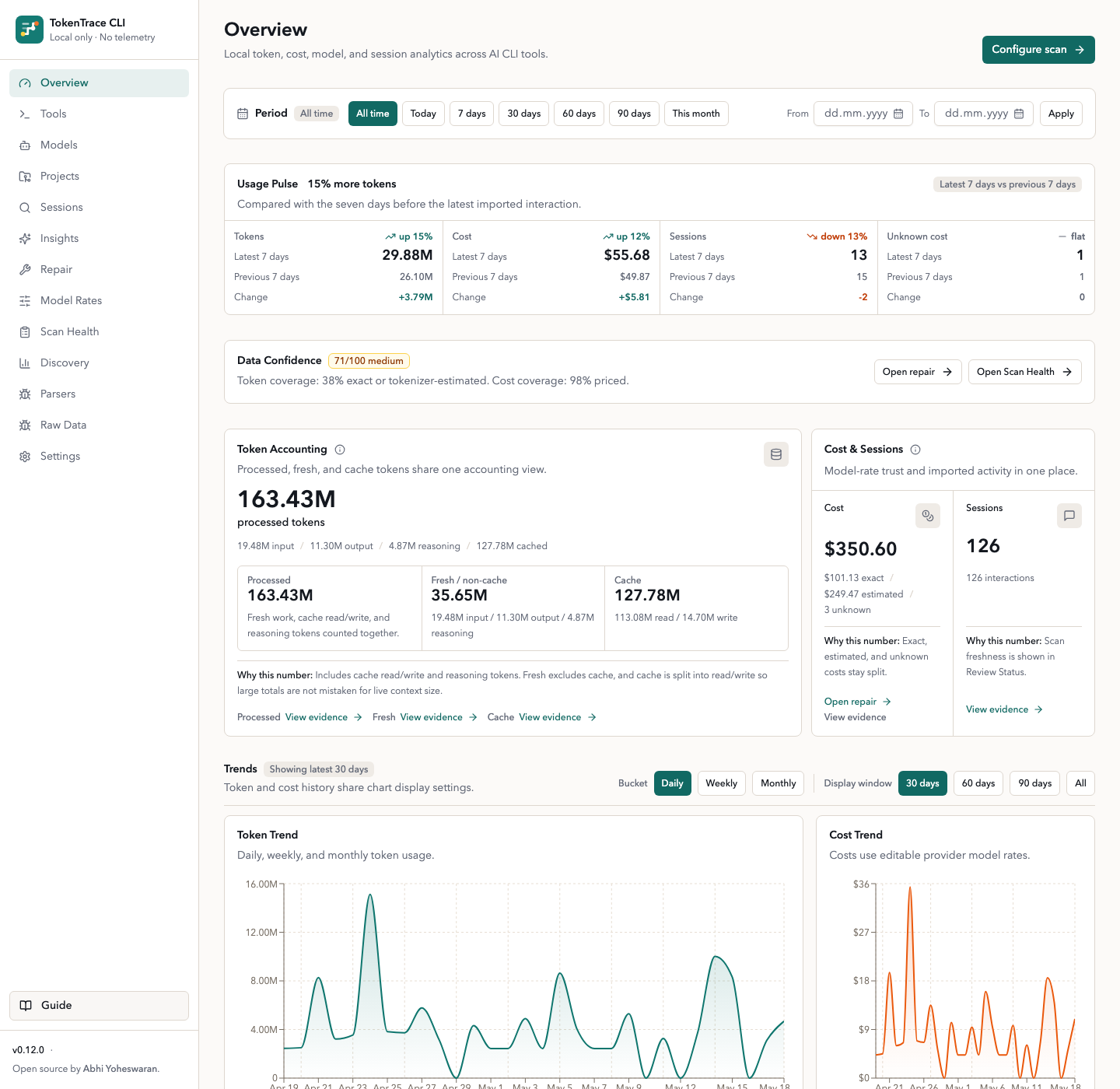
Evidence-first overview
Every total points back to what produced it
Four surfaces tied together: the Overview pulse and metric cards link into evidence trails, unknown cost has its own Repair workflow, and Scan Health carries the Parser Trust Report, Scan History Diff, scan scheduling, and supply-chain IOC checks. Every record carries a Data Confidence score; the same evidence behind any total can be exported as an Evidence Pack.
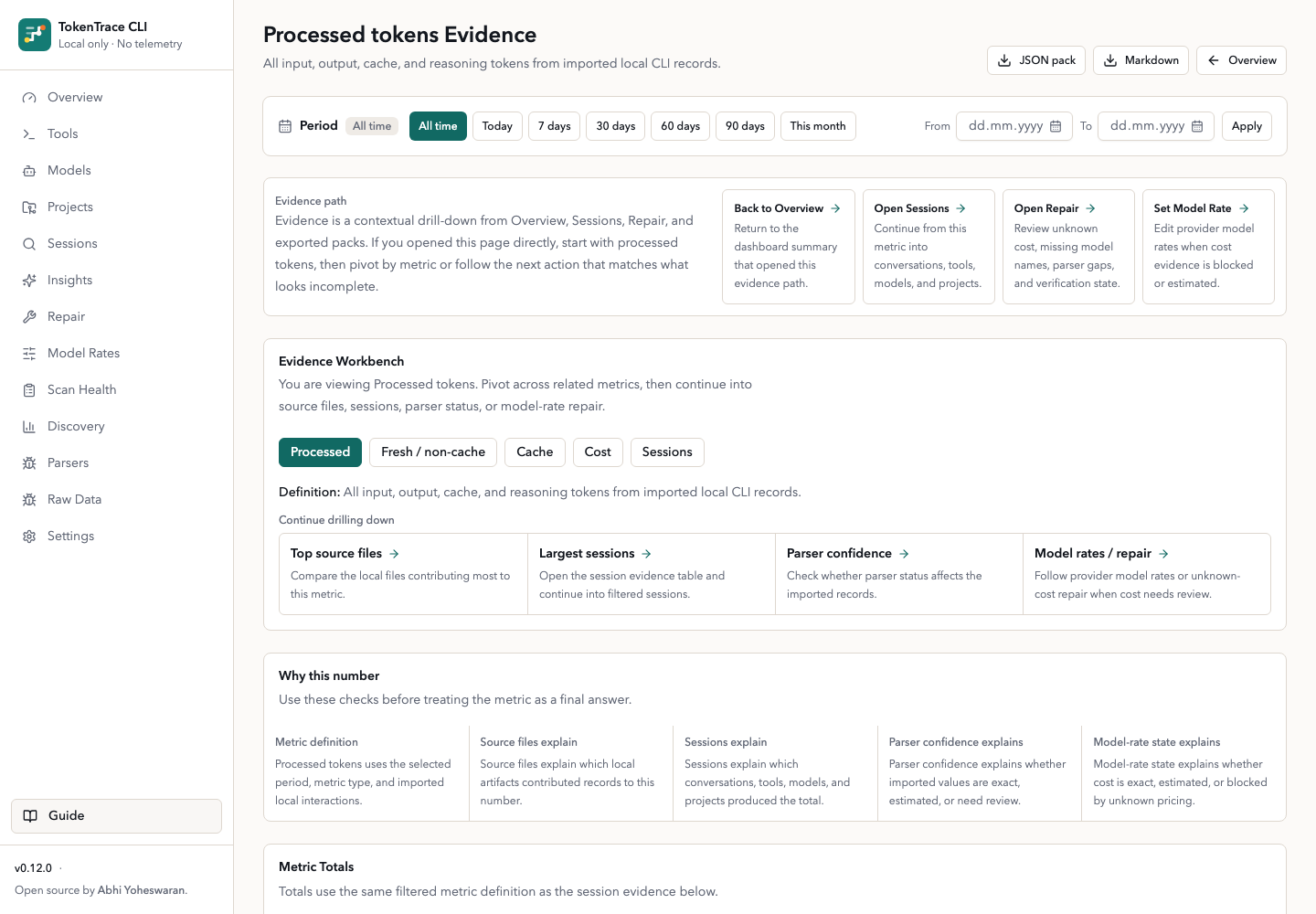
tokentrace evidence --json prints the same trail for local automation, and Evidence Packs export the entire pack as JSON or Markdown.
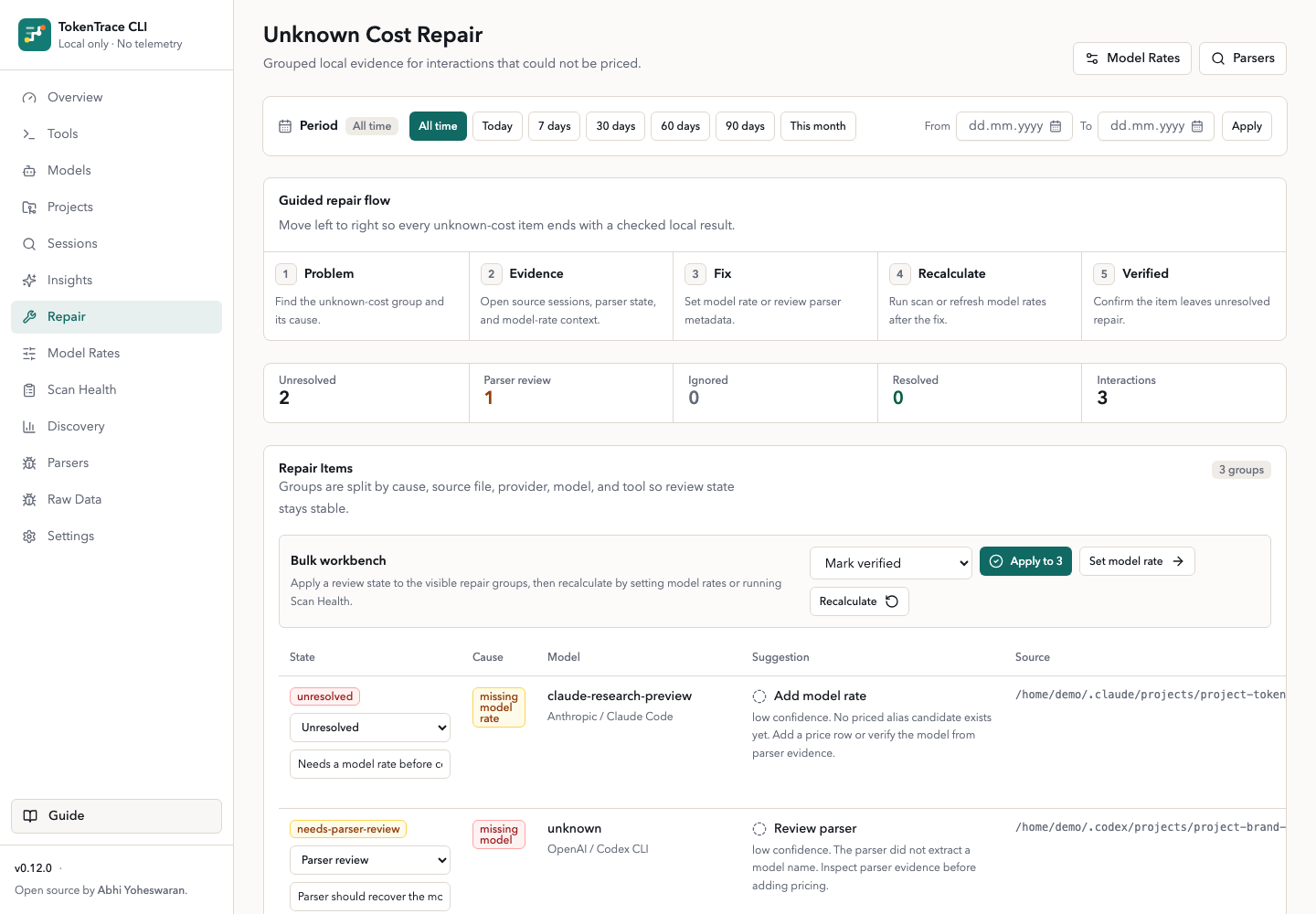
tokentrace repair --json prints the same groups for scripting.
Release notes
Shipped in 0.14.x
The MCP agent adoption and stabilization line. TokenTrace ships a first-class Model Context Protocol entry point so coding agents can adopt it without inventing a wrapper.
- Local stdio MCP server.
tokentrace mcpstarts a read-only server underio.github.abhiyoheswaran1/tokentrace, exposingget_status,run_doctor,get_evidence,get_repair_queue,get_report, andrun_scan. No files scanned at startup. - Grounded by default. Agents call
get_agent_guidefirst to load the privacy model and guardrails; every response carries agent-decisive metadata;run_scanrefuses withoutconfirmLocalScan=true. - Verifiable + resilient.
tokentrace mcp selftest --jsonverifies startup without local file reads; data-backed CLI help stays safe on fresh or broken local databases. Adoption docs indocs/agent-adoption.md,TOKENTRACE_AGENT.md, andllms.txt.
Package trust
What npm install tokentrace runs
No install scripts. npm install tokentrace runs zero TokenTrace code. The package has no preinstall, install, or postinstall hooks.
npm provenance. Every release ships an npm provenance attestation, so anyone can check on npm that the published package matches the public source repo.
Readable source. The published package ships readable application source and the compiled CLI runtime, not generated route bundles. Anyone can read what actually runs.
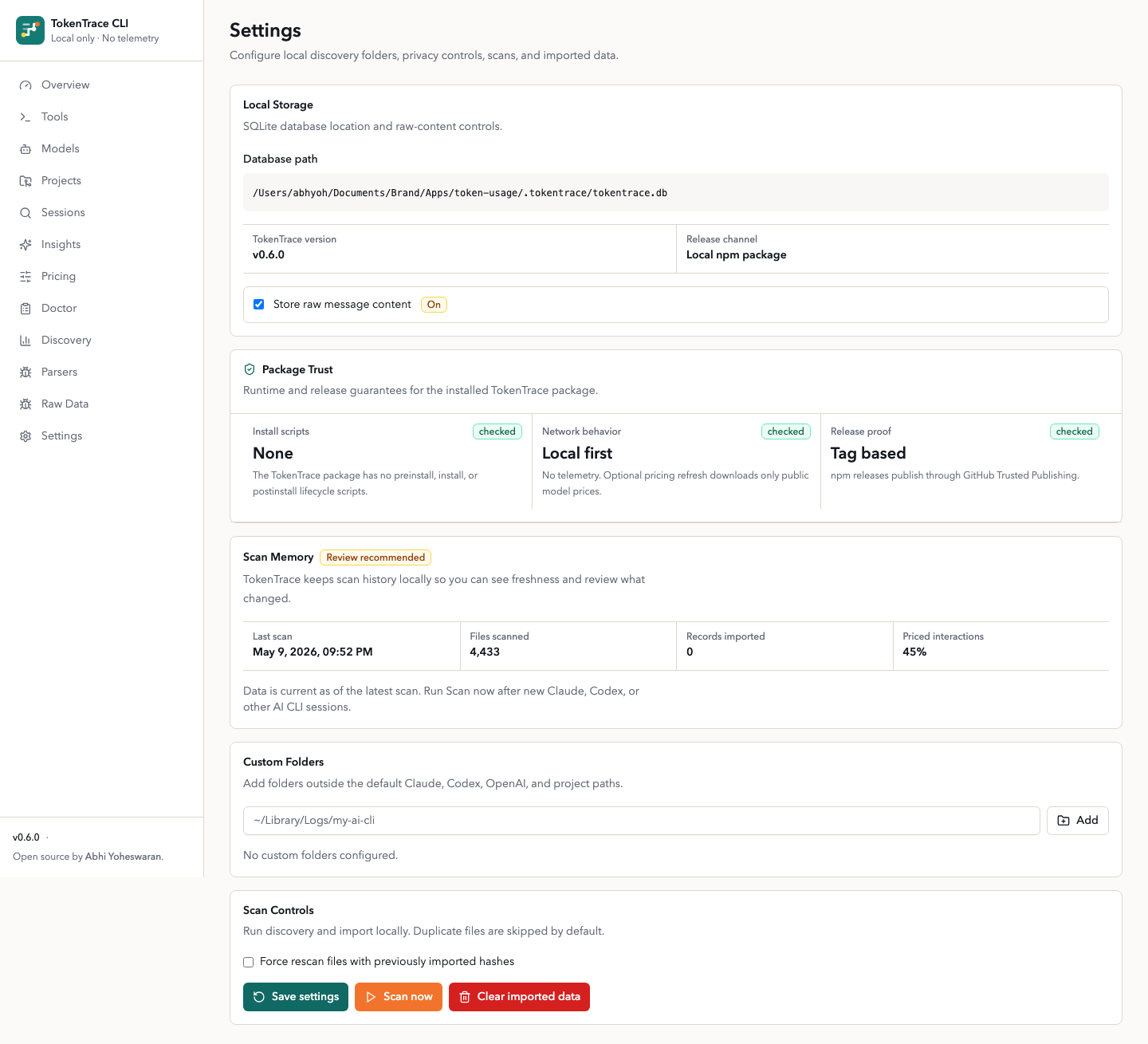
Settings, Package trust. The same guarantees, surfaced inside the running app.
Privacy
TokenTrace runs locally, does not bill users, and only uses Model Rates to estimate provider costs.
Local files stay local. TokenTrace reads files the AI CLIs already write on your disk. No scraping, no extensions, no traffic interception, no proxy, no MITM, no telemetry. Raw prompt and response bodies are not stored by default. The only optional outbound network call refreshes public Model Rate data so the local cost estimate is accurate. No accounts, no billing.
Quick start
From npx to status line
npx tokentrace # run without installing; opens the local dashboard npx tokentrace mcp # start a local stdio MCP server for agents tokentrace mcp selftest --json # verify MCP startup; does not scan files tokentrace agent --json # read-only agent discovery manifest tokentrace doctor --json # inspect Scan Health and repair recommendations tokentrace evidence --json # trace metric totals to their source records
Total downloads
About
Where it fits
TokenTrace is one of two related developer-tools projects on this site. ProjScan gives AI coding agents real structural facts about your codebase. TokenTrace shows you, after the fact, what those agents and their CLIs actually cost.
The scope stays narrow on purpose. Ingestion reads only the local filesystem. Desktop scraping, browser extensions, traffic interception, and cloud telemetry change the trust profile, so they are not on the roadmap.
Every record carries a Data Confidence label (exact, tokenizer estimate, or simple estimate) and a Model Rate coverage flag, so any aggregate splits back into what was measured and what was estimated.